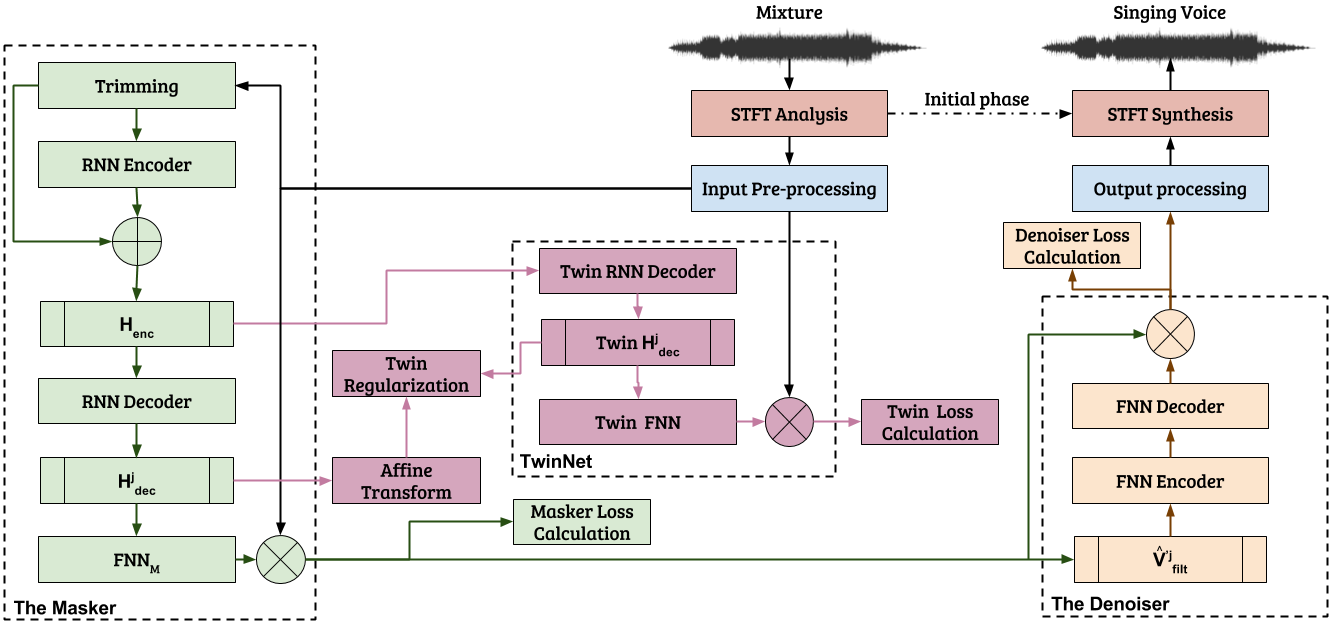
MaD TwinNet
Our method is based on our previously
proposed
Masker-Denoiser architecture, augmented with the recently proposed
Twin Network. Thus, the "MaD" is from the
"Masker-Denoiser" and TwinNet from the Twin Network.
Below you can see an illustration of our method.
Illustration of the MaD TwinNet
MaD in a nutshell
Our method accepts as an input the audio mixture. After the initial pre-processing (e.g. time-frequency
transformation, more info at the paper), the masker accepts as an input the magnitude spectrogram of the
mixture.
Then, the Masker predicts and applies a time-frequency mask to its input and outputs a first estimate of
the
magnitude spectrogram of the singing voice. This first estimate is then given as an input to the
Denoiser.
The Denoiser predicts and applies a time-frequency denoising filter. This filter aims at removing
interferences,
artifacts, and (in general) any other noise introduced to the first estimate of the singing voice.
After the application of the denoising filter by the denoiser, the now cleaned estimated of the
magnitude
spectrogram of the singing voice is turned back to audio samples by the output processing.
And what about TwinNet?
The recently proposed
TwinNet is an effective way to make a recurrent neural network (RNN)
to
anticipate for upcoming patterns, i.e. to make the RNN to
be
able to respond better to the future, by learning global structures of the singing voice.
We adopted the TwinNet as a way to make the
MaD learn to anticipate the strong temporal patterns and structures
of
music. Demo section